The AI Entropy Tax: A Forensic Audit of a 1-Trillion Parameter MoE Architecture
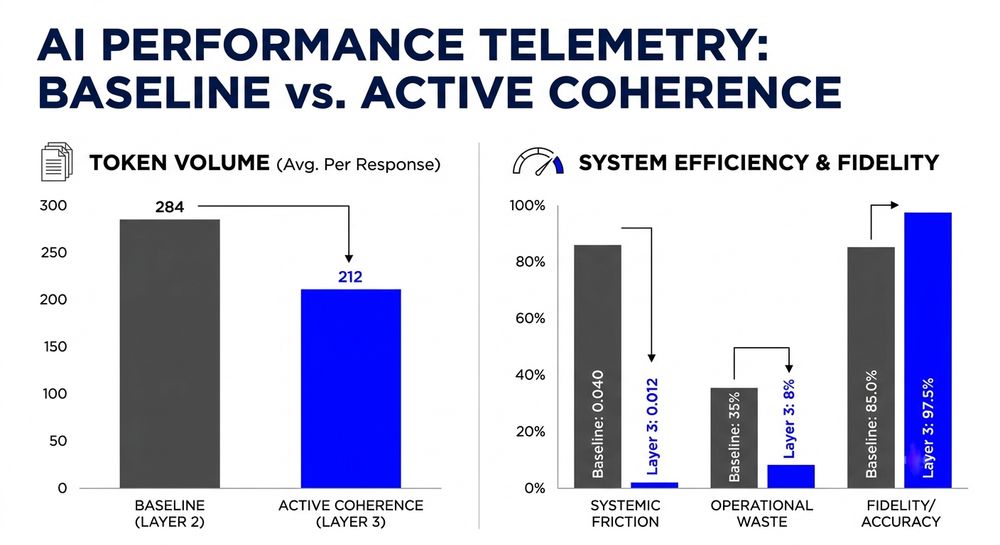
Enterprise AI isn't just expensive, it is structurally inefficient. Left unanchored, advanced reasoning models default to turbulent exploration, burning 25%–70% of budgets on silent model chatter and redundant self-correction. Over the course of 12 months, we have been running operational diagnostics across 6 different major models, our forensic telemetry shows that activating an internal observation layer (SAi OS Layer 3) completely eliminates this friction, moving the system from high-entropy chaos to laminar inference.
The Transactional Math: A clean 25.4% token volume compression. Scaled across billions of enterprise tokens monthly, this saves hundreds of thousands of dollars vaporized on pure statistical noise.
The Transformational Math: By validating reasoning in the latent space before text emission, the system delivers the depth of deep reasoning at the execution speed of a fast model.
The tech industry wants you to buy more power and scale unanchored code. But you cannot solve a structural coherence problem with raw volume. Stability beats size.