Yesterday I called out Token Maxing: the 2026 version of busy work where you run circles with prompts and feel productive while your actual outcomes stay flat.
So how do you actually Output Max?
It's not a magic prompt. It's a system. Here's the framework I use.
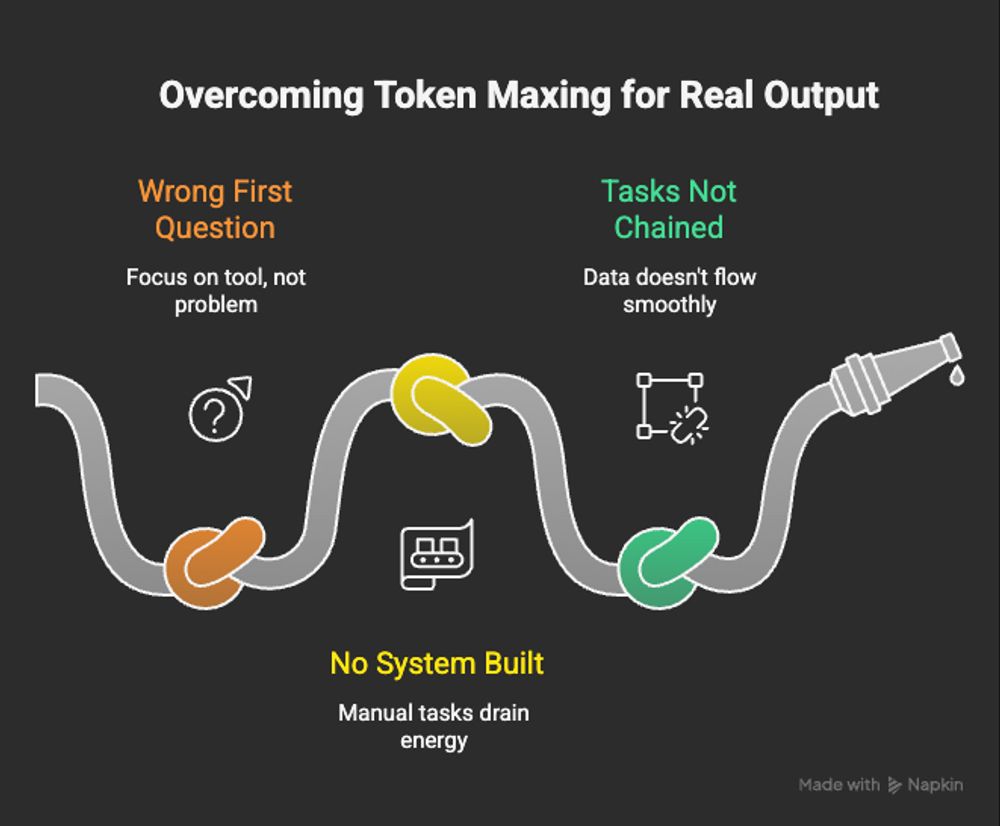
Start with the friction, not the tool. Most people open Gemini and ask "what can this do?" Wrong first question. The right question is: where is my workflow leaking energy? Is it the two hours you spend synthesizing research? Is it manually moving notes from a meeting into your project board? Output Maxing starts with a real problem, not a feature list.
Build the conveyor belt. Once you have the problem, don't just throw a chatbot at it. Map the flow first (Mermaid.ai). Chain the tasks (Google Workflows). Connect the pieces (Google Stitch). Instead of running 10 prompts manually, you build something where data flows in, gets processed, and lands on your desk ready for a final judgment call. That's a system. That's Output Maxing.
The Taste Test
This is where the real work lives. Once the output arrives, you don't just hit send. You ask: does this sound like a human or a machine trying to pass as one? Does this solve the client's actual problem, or just the one they asked for? Is it grounded?
AI provides the scale. You provide the soul.
Here's the reality: Output Maxing isn't about working more with AI. It's about working less on "stuff" so you can spend your 3 billion seconds of experience on the things that actually matter.
Which step in your workflow is leaking the most energy right now?
#AI #SystemsThinking #FutureOfWork #OutputMaxing #HumanFirst
P.S. The framework only works if you're honest about where the friction actually lives. Most people already know the answer. They just haven't stopped moving long enough to look at it.